Delta Table Z-Ordering
What is Z-Ordering in Delta Tables ?
Z-ordering is a technique in Delta Lake that improves query performance by clustering data based on the values of specific columns, creating a spatially-optimized layout. It's particularly useful for faster data retrieval in scenarios with selective queries, especially those using filters.
Here's how Z-ordering works in Delta Tables:
1.Data Clustering: When you apply Z-ordering on certain columns in a Delta Table, Delta Lake reorders data files by co-locating rows with similar column values together. This co-location significantly improves data skipping capabilities, allowing queries to read less data.
2.Spatial Indexing: It’s inspired by Z-order curves, which map multi-dimensional data into a one-dimensional space while preserving locality. This means rows with similar values are placed near each other on disk, improving read efficiency.
3.Data Skipping: With Z-ordering, Delta Lake can skip irrelevant data files more efficiently. This is especially beneficial when querying large tables on frequently filtered columns. Z-ordering helps minimize the number of data files that need to be scanned, reducing I/O and improving performance.
When to Use Z-ordering?
Z-ordering is most effective when:
1. You have large datasets.
2. There are specific columns that are frequently used in filter conditions.
3. Queries need to access a subset of data based on specific column values (e.g., date, region, or product ID).
Lets understand Z-Ordering with an Example
First create a Delta table with dummy records.
df_data=spark.sql("""
WITH CTE AS (
SELECT
CAST(ABS(RAND() * 50000000) AS INT) AS id,
CAST(ABS(RAND() * 40) AS INT) + 60 AS random_score
FROM RANGE(100000000)
)
SELECT id, CONCAT('Person ', id) AS name, random_score
FROM CTE
""")
df_data.write.mode("overwrite").saveAsTable("random_score")
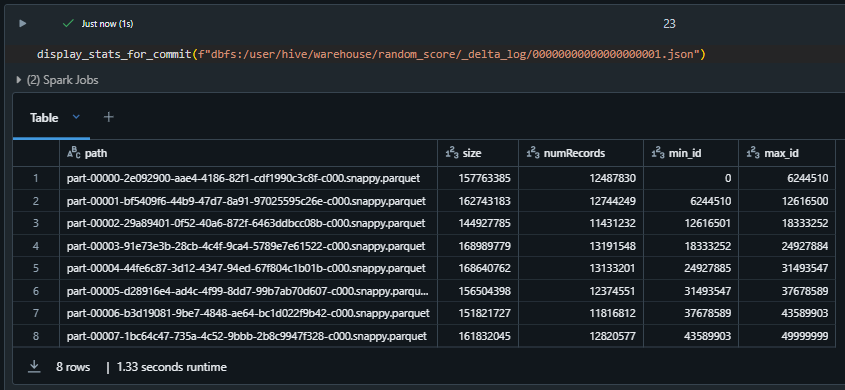
We can see there are total 8 files created for the delta table and each file is having 160 mb in size.
display(dbutils.fs.ls("dbfs:/user/hive/warehouse/random_score"))

Now let's run a query
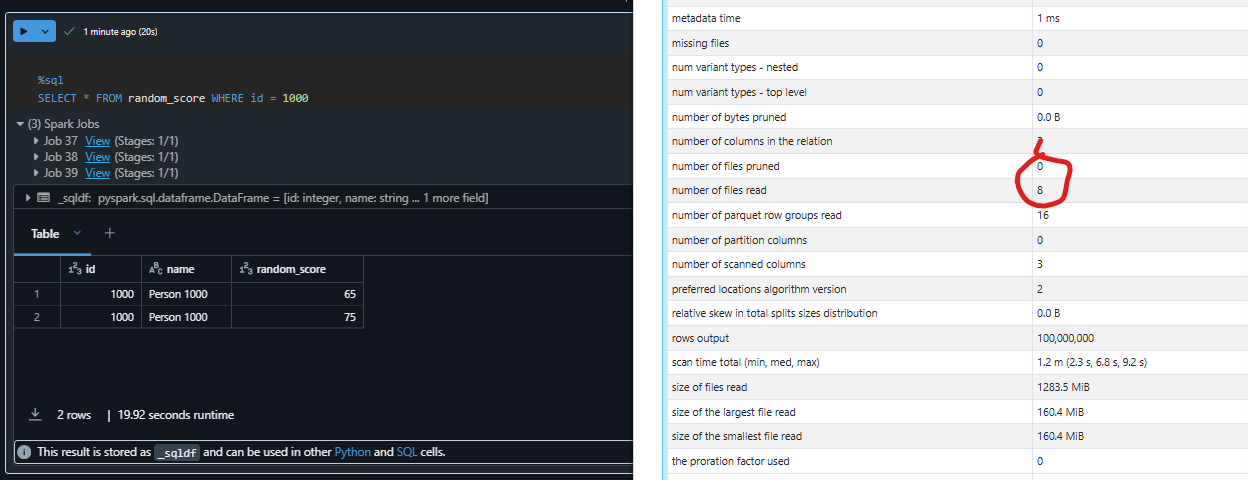
If you closly look at the above query statistics then you can see the overall query execution time is around 20 seconds and spark has to read all the files in order to search the records which is having id as 1000.
The reason is each Parquet file contains the expected 12.5 million records, but each file includes a range of IDs covering the full span from 0 to 50 million. As a result, Spark’s file statistics indicate that records with an ID of 1000 could potentially reside in any of these files, necessitating a scan of all files.
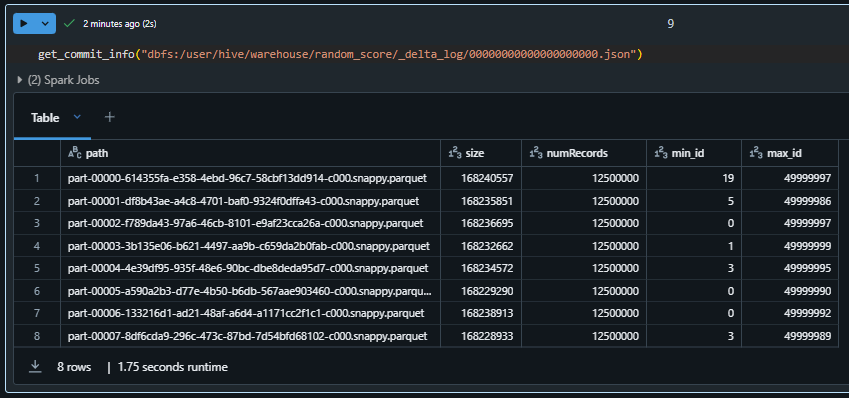
Use below code snippet to extract commit info
from pyspark.sql.functions import *
from pyspark.sql.types import *
def get_commit_info(path):
schema = StructType(
[
StructField("numRecords", LongType(), True),
StructField(
"minValues",
StructType(
[
StructField("id", LongType(), True),
StructField("name", StringType(), True),
StructField("random_score", LongType(), True),
]
),
True,
),
StructField(
"maxValues",
StructType(
[
StructField("id", LongType(), True),
StructField("name", StringType(), True),
StructField("random_score", LongType(), True),
]
),
True,
),
]
)
(
spark.read.json(path)
.select("add")
.where("add is not null")
.selectExpr("add.path", "add.size", "add.stats")
.withColumn("stats", F.from_json(F.col("stats"), schema))
.withColumn("numRecords", F.expr("stats.numRecords"))
.withColumn("min_id", F.expr("stats.minValues.id"))
.withColumn("max_id", F.expr("stats.maxValues.id"))
.drop("stats")
.orderBy("path")
.display()
)
get_commit_info("dbfs:/user/hive/warehouse/random_score/_delta_log/00000000000000000000.json")
Now let's perform Z-order on the existing table and see what happens.
Before performing the Z-order, a custom value will be set for the maximum file size in the OPTIMIZE command. For demonstration purposes, instead of using the default of 1GB, I’ll set it to 160MB—roughly the same size as the files in the original source table. The goal here is not compaction but rather to observe the impact of Z-ordering.
spark.conf.set("spark.databricks.delta.optimize.maxFileSize", str(1024 * 1024 * 160))
%sql
OPTIMIZE source ZORDER BY (id)
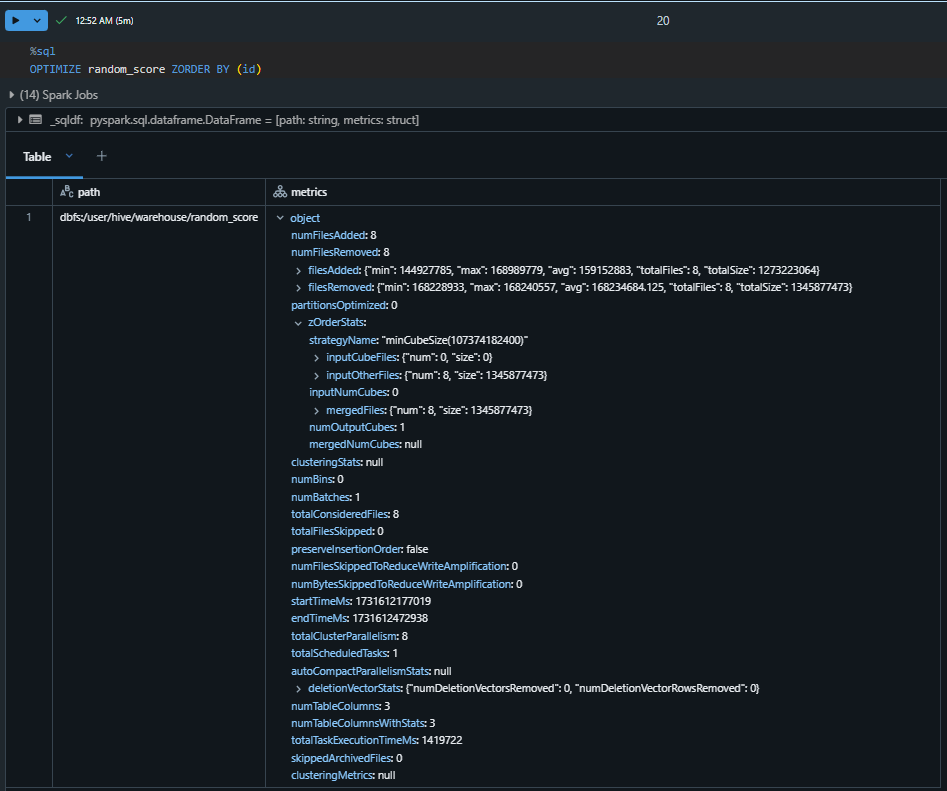
As Z-order optimization command is successfully executed on the table, now lets check how it effected the query performance.
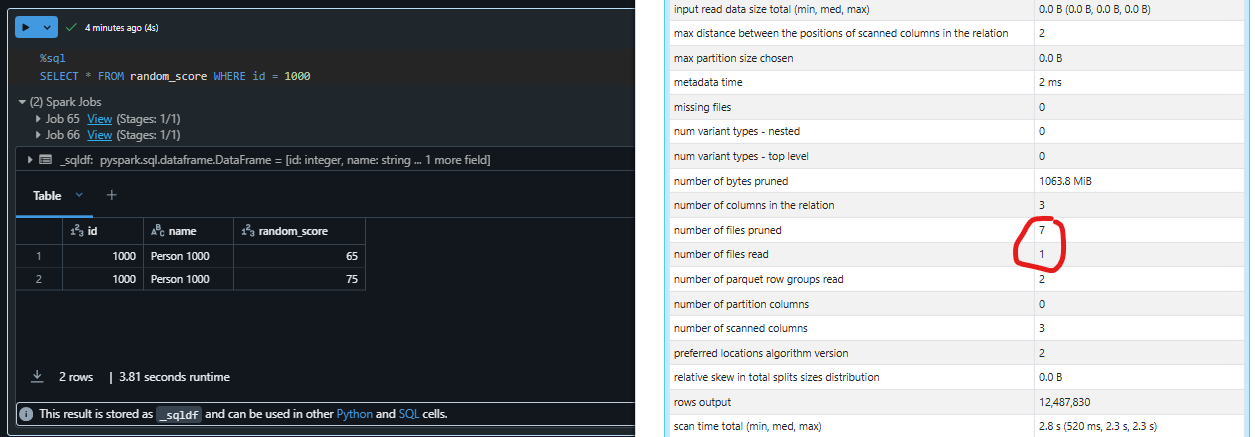
Now after Z-Ordering our query is taking only 4 seconds to execute and spark is only reading one file.
Lets take a look at the file statistics.